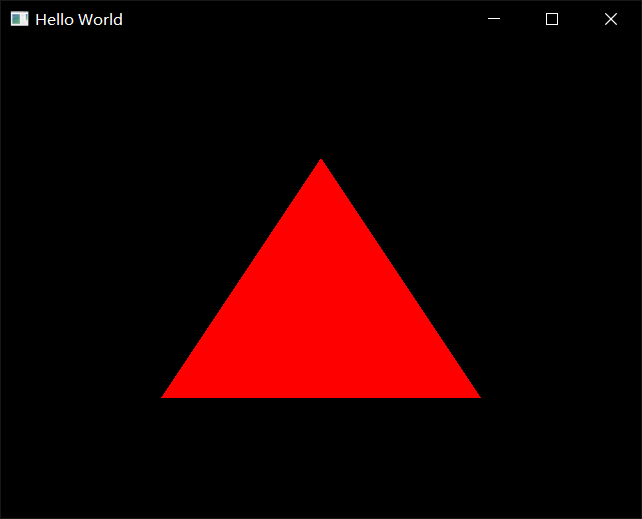
01 Introduction 02 Setting up Opengl and Creating a Window in C++ thecherno.com/discord
提供窗口的创建与管理——GLFW(多平台)
我们当然可以下载glfw源码作为静态库在项目中编译
为了方便选择预编译的二进制文件,配置环境这一部分在C++里已经做过了
这个时候直接允许文档的参考代码,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <GLFW/glfw3.h> int main (void ) GLFWwindow* window; if (!glfwInit ()) return -1 ; window = glfwCreateWindow (640 , 480 , "Hello World" , NULL , NULL ); if (!window) { glfwTerminate (); return -1 ; } glfwMakeContextCurrent (window); while (!glfwWindowShouldClose (window)) { glClear (GL_COLOR_BUFFER_BIT); glfwSwapBuffers (window); glfwPollEvents (); } glfwTerminate (); return 0 ; }
可以编译成功,但是链接出现了问题
无法解析的外部符号__imp__glClear@4
我们知道这是链接的问题,我们需要找到一个glClear函数,在一个我们没有添加的库文件中。
这个库文件就是OpenGL32.lib
(https://blog.csdn.net/qq_41524721/article/details/104330656这个博客也给出了这个解决方案。)
这样我们成功地允许了文档的参考代码,画出了一个窗口
(Cherno教程当中还有一些关于平台注册的函数的连接失败,User32.lib 、Gid32.lib、Shell32.lib,我之所以没有出现这个问题,发现在项目设置的连接器命令行里已经处理过了。。。从项目默认继承也不知道咋继承出来的,但是缺少库文件,就该这样链接)
1 2 3 4 5 6 7 glBegin(GL_TRIANGLES); glVertex2f(-0.5f,-0.5f) glVertex2f(0.0f,0.5f) glVertex2f(0.5f,-0.5f) glEnd();
03 Using Modern Opengl in C++ 如介绍中所说,Opengl的规范是显卡制造商实现的,因此我们需要做的是进入驱动程序,“获取”函数并调用(访问驱动程序dll文件并检索指向库中函数的指针)
理论上这是可以手动操作的,但无法跨平台。
而能够实现这些操作的库:
glew(opengl extention wrangler)
glad
教程将会使用Glew
http://glew.sourceforge.net/
我们同样只要关注include和lib文件夹(下载的压缩包里顺便有文档)
第一件事是创建一个有效的opengl渲染上下文(contex),然后使用glewInit()去初始化扩展入口点(initialize the extension entry points)
注意lib里面有两个文件
技术上这两个链接库都是静态的,但是glew32.lib是链接到dll使用的。glew32s.lib(static)
1 2 3 4 5 6 7 #include <GLFW/glfw3.h> #include <GL/glew.h> ... if (!glfwInit ()) return -1 ; glewInit (); ...
如果这样去include的话,会收获一个错误fatal error C1189: #error: gl.h included before glew.h
双击这个错误我们可以在 glew.h中看到定义
1 2 3 #if defined(__gl_h_) || defined(__GL_H__) || defined(_GL_H) || defined(__X_GL_H) #error gl.h included before glew.h #endif
所以我们应该把glew放到前面。
但是这部操作之后,我们发现了链接错误
error LNK2019: 无法解析的外部符号 __imp__glewInit@0,函数 _main 中引用了该符号
但是链接按理来说应该是正确的。在glew.h中搜索glewInit的定义,
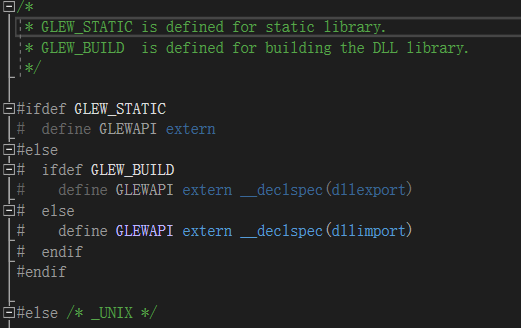
可以看到在实际返回类型前有一个GLEWAPI的宏定义
我们没有定义GLEW_STATIC和 GLEW_BUILD,所以把GLEWAPI定义为了extern __declspec(dllimport)
这是一个 内置的msvc编译器,告诉链接器它来自于一个dll文件,所以需要dll引用,但是我们没有用dll版本的 glew。
所以我们要做的是——自己定义(其实这些文档里都有)
这回又可以画好我们的三角形了。但是如果按照文档运行
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <GL/glew.h> #include <GL/glut.h> ... glutInit (&argc, argv);glutCreateWindow ("GLEW Test" );GLenum err = glewInit (); if (GLEW_OK != err){ fprintf (stderr, "Error: %s\n" , glewGetErrorString (err)); ... } fprintf (stdout, "Status: Using GLEW %s\n" , glewGetString (GLEW_VERSION));
我们将会失败,因为glewInit是有返回值的,这个失败说明初始化并不成功。
因为我们需要先创建一个==opengl渲染上下文==。
而这个上下文就是
1 glfwMakeContextCurrent (window);
把glew初始化放在这之后就成功了。
我们还可以输出我们的 opengl版本号(这与glew无关)
1 std::cout<<glGetString (GL_VERSION)<<std::endl;
可以看到我的输出是:
4.6.0 NVIDIA 462.30
04 Vertex Buffers and Drawing a Triangle Vertex Buffer顶点缓冲区就是一个(内存)缓冲区,实质是一个数组字节的内存。
区别是这是Opengl中的内存缓冲区,这表明它实际在我们的GPU中(显存VRAM)
当我们定义一组数据来表示三角形,将它存进GPU的VRAM中,然后我们需要调用DrawCall,让GPU从VRAM中读数据。
此外,我们还需要告诉GPU如何读取和解释数据,以及如何把它放到屏幕上。
关于渲染管线,就不赘述了。
还要记住 Opengl是一种状态机。
1 2 3 unsigned int buffer;glGenBuffers (1 , &buffer);
这就是实际对象的id,无论它储存顶点还是纹理…
那么我们就需要表示这块缓冲区如何使用 。
1 2 3 4 unsigned int buffer;glGenBuffers (1 , &buffer);glBindBuffer (GL_ARRAY_BUFFER, buffer);
而下一步就应该向缓冲区里传入数据。
我们可以创建缓冲区时指定大小,然后直接给出数据;或者什么都不给,用数据来更新。
我们现在为它提供绘制三角形的数据
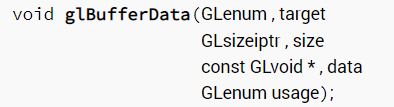
1 2 3 4 5 6 7 8 9 float positions[6 ] = { -0.5f , -0.5f , 0.0f , 0.5f , 0.5f , -0.5f }; ... glBufferData (GL_ARRAY_BUFFER, sizeof (positions), positions, GL_STATIC_DRAW)
查文档啥都有 https://docs.gl/ ,这里包含了各种版本opengl的文档
非常好用(刚才我们看过opengl版本了,所以是gl4)
下面也有每个参数的含义
关于usage,是如何访问缓冲区对象的数据储存区的提示。包括访问频率(STREAM修改一次,最多使用几次,STATIC修改一次多次使用,DYNAMIC反复修改并多次使用)和访问性质(DRAW,READ,COPY)
静态和动态是最常用的。静态表示我们只创建一次缓冲区,不会每一帧都修改buffer,但是每一帧都绘制。
但要注意这只是一个Hint提示,即便声明静态,每一帧更新缓冲区仍然可以工作,只是会慢很多。
通常到这里我们还需要创建Index buffer,但是这里就先不用了
我们再来看这一串,就是在显存建立缓冲区,并指定缓冲区对象的名称(用途),最后把CPU内存的数据拿给显存
1 2 3 4 5 6 7 8 9 10 11 float positions[6 ] = {-0.5f , -0.5f ,0.0f , 0.5f ,0.5f , -0.5f }; unsigned int buffer;glGenBuffers (1 , &buffer);glBindBuffer (GL_ARRAY_BUFFER, buffer);glBufferData (GL_ARRAY_BUFFER, sizeof (positions), positions, GL_STATIC_DRAW);
但是我们依然不知道如何使用这6个浮点数据。
我们也没有着色器来指定如何绘制 这些数据。这是之后的内容
但是如果要绘制的话,可以这样
1 2 glDrawArrays(GL_TRIANGLES,0,3);//我们没有index buffer,可以这样做 //Mode,First(starting index),Count(number of indices)
另一种方式是
1 2 3 4 5 glDrawElements(GL_TRIANGLS,3,GL_UNSIGNED_INT,indices)//和idnex buffer一起使用 //Mode //count //type:Must be one of GL_UNSIGNED_BYTE, GL_UNSIGNED_SHORT, or GL_UNSIGNED_INT //indices
这就是DrawCall
注意Opengl的状态机性质,因为前面绑定了这个三角形的数据,所以drawcall就会绘制这个三角形
05 Vertex Attribute and Layouts in Opengl 总结一下,Opengl的管线工作流程就是为显卡提供数据,然后储存进GPU显存,包含了所有数据。我们会使用着色器程序在gpu上执行,去读取数据然后进行绘制。
当着色器读取数据时,顶点缓存需要知道缓存数据的布局==Layout==——这是一堆浮点数,包含每个顶点的位置、法线、纹理坐标。。。因此我们需要告诉Opengl内存的数据是如何布局的 。
顶点数据内储存了各种属性,而绑定属性的方式就是顶点属性指针
1 2 3 4 5 6 7 8 9 void glVertexAttribPointer ( GLuint index, GLint size, GLenum type, GLboolean normalized, GLsizei stride, const GLvoid * pointer)
noramlized
规范化设置
如果规范化设置为GL_TRUE ,则表示以整数格式存储的值在被访问并转换为浮点时将映射到范围 [-1,1](对于有符号值)或 [0,1](对于无符号值)。否则,值将直接转换为浮点数,而无需规范化。GL_FLOAT的设置已经规范了
stride
连续通用顶点属性之间的字节偏移量:每个顶点之间的字节数量
比如我们有一个位置3float,uv坐标2 float,法线3*float 12bytes+8bytes+12bytes,stride = 32bytes
可以想象Opengl从一个顶点属性跳到下一个顶点的属性,就直接根据步幅寻找
point
指定当前绑定到目标的缓冲区的数据存储区中数组中第一个通用顶点属性的第一个组件的偏移量。。。缩句,数组的第一个属性的第一个组件的偏移量
初始为0。
比如位置是0,uv是12bytes(12),法线是20bytes(20)
C++有提供偏移类的宏
注意这里需要const void*,因此需要如转换(const void*) 8
我们还需要启用这个顶点属性
1 glEnableVertexArrayAttrib (0 );
1 2 3 4 5 6 7 8 9 10 11 12 13 float positions[6 ] = {-0.5f , -0.5f , 0.0f , 0.5f , 0.5f , -0.5f }; unsigned int buffer;glGenBuffers (1 , &buffer);glBindBuffer (GL_ARRAY_BUFFER, buffer);glBufferData (GL_ARRAY_BUFFER, sizeof (positions), positions, GL_STATIC_DRAW);glVertexAttribPointer (0 , 2 , GL_FLOAT, GL_FALSE, 2 * sizeof (float ),0 );glEnableVertexAttribArray (0 );
以上CPU阶段的准备工作就完成了,接下来调用drawcall,就开始执行着色器程序了。
06 How a Shader Work in Opengl 实际上这个时候我们不写着色器,屏幕上已经可以画出三角形了。这是因为如果我们没有写自己的着色器的话,一些GPU会提供默认着色器。
回顾vs和fs的区别,vs对于每个顶点运行,fs对于每个像素运行。假如三角形非常巨大,那么同样的运算,vs只需要执行3次,fs则需要执行像素数的次数。这个特性可以用于一些性能优化。
其他关于shader的内容就不赘述了。
07 Writing a Shader in Opengl 我们需要定义一个新的函数,并且是静态的。因为不希望它在其他cpp文件中使用。
它用来编译我们的着色器代码。
着色器代码可以来自不同地方 ,我们可以简单地只写一个字符串。也可以从文件读取。
我们需要让Opengl编译这个程序,把vs和fs连接到一个单独的着色器程序中,并返回某种唯一的标识符,所以我们可以绑定一个着色器,然后像使用顶点缓冲那样,生成一个缓冲并返回一个id去使用它。(生成缓冲区-绑定-传递)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 static unsigned int ComplieShader (unsigned int type, const std::string& source) unsigned int id = glCreateShader (type); const char * src = source.c_str (); glShaderSource (id, 1 , &src, nullptr ); glCompileShader (id); int result; glGetShaderiv (id, GL_COMPILE_STATUS, &result); if (!result){ int length; glGetShaderiv (id, GL_INFO_LOG_LENGTH, &length); char * message =(char *) alloca (length * sizeof (char )); glGetShaderInfoLog (id, length, &length, message); std::cout<<"Fail to complie" <<(type == GL_VERTEX_SHADER ? "vertex" : "fragment" ) << "shader!" <<std::endl; std::cout<<message<<std::endl; glDeleteShader (id); return 0 ; } return id; } static unsigned int CreateShader (const std::string& vertexShader, const std::string& fragmentShader) unsigned int program = glCreateProgram (); unsigned int vs = ComplieShader (GL_VERTEX_SHADER,vertexShader); unsigned int fs = ComplieShader (GL_FRAGMENT_SHADER,fragmentShader); glAttachShader (program, vs); glAttachShader (program, fs); glLinkProgram (program); glValidateProgram (program); glDeleteShader (vs); glDeleteShader (fs); return program; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void glShaderSource (GLuint , shader GLsizei , count const GLchar **, string const GLint *length)
着色器的编译和传递方法就完成了。
接下来我们编写着色器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 std::string vertexShader = "#version 330 core\n" "\n" "layout(location = 0) in vec4 position;\n" "\n" "void main()" "{\n" " gl_Position = position;\n" "}\n" ; std::string fragmentShader = "#version 330 core\n" "\n" "layout(location = 0) out vec4 color;\n" "\n" "void main()" "{\n" " color = vec4(1.0,0.0,0.0,1.0);\n" "}\n" ; unsigned int shader = CreateShader (vertexShader,fragmentShader);glUseProgram (shader);
非常顺利
再检查着色器的错误处理
源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #include <GL/glew.h> #include <GLFW/glfw3.h> #include <iostream> static unsigned int ComplieShader (unsigned int type, const std::string& source) unsigned int id = glCreateShader (type); const char * src = source.c_str (); glShaderSource (id, 1 , &src, nullptr ); glCompileShader (id); int result; glGetShaderiv (id, GL_COMPILE_STATUS, &result); if (!result) { int length; glGetShaderiv (id, GL_INFO_LOG_LENGTH, &length); char * message = (char *)alloca (length * sizeof (char )); glGetShaderInfoLog (id, length, &length, message); std::cout << "Fail to complie" << (type == GL_VERTEX_SHADER ? "vertex" : "fragment" ) << "shader!" << std::endl; std::cout << message << std::endl; glDeleteShader (id); return 0 ; } return id; } static unsigned int CreateShader (const std::string& vertexShader, const std::string& fragmentShader) unsigned int program = glCreateProgram (); unsigned int vs = ComplieShader (GL_VERTEX_SHADER, vertexShader); unsigned int fs = ComplieShader (GL_FRAGMENT_SHADER, fragmentShader); glAttachShader (program, vs); glAttachShader (program, fs); glLinkProgram (program); glValidateProgram (program); glDeleteShader (vs); glDeleteShader (fs); return program; } int main (void ) GLFWwindow* window; if (!glfwInit ()) return -1 ; window = glfwCreateWindow (640 , 480 , "Hello World" , NULL , NULL ); if (!window) { glfwTerminate (); return -1 ; } glfwMakeContextCurrent (window); if (glewInit () != GLEW_OK) std::cout << "GlewInit fail!" << std::endl; float positions[6 ] = { -0.5f , -0.5f , 0.0f , 0.5f , 0.5f , -0.5f }; unsigned int buffer; glGenBuffers (1 , &buffer); glBindBuffer (GL_ARRAY_BUFFER, buffer); glBufferData (GL_ARRAY_BUFFER, sizeof (positions), positions, GL_STATIC_DRAW); glVertexAttribPointer (0 , 2 , GL_FLOAT, GL_FALSE, 2 * sizeof (float ),0 ); glEnableVertexAttribArray (0 ); std::string vertexShader = "#version 330 core\n" "\n" "layout(location = 0) in vec4 position;\n" "\n" "void main()" "{\n" " gl_Position = position;\n" "}\n" ; std::string fragmentShader = "#version 330 core\n" "\n" "layout(location = 0) out vec4 color;\n" "\n" "void main()" "{\n" " color = vec4(1.0,0.0,0.0,1.0);\n" "}\n" ; unsigned int shader = CreateShader (vertexShader, fragmentShader); glUseProgram (shader); while (!glfwWindowShouldClose (window)) { glDrawArrays (GL_TRIANGLES, 0 , 3 ); glfwSwapBuffers (window); glfwPollEvents (); } glDeleteShader (shader); glfwTerminate (); return 0 ; }